
Most teams jump straight to “training the model” when what they actually need is a system that answers questions using their latest, approved internal documents. That is exactly where the decision between RAG and fine tuning matters.Most teams jump straight to “training the model” when what they really need is accurate, traceable answers from the latest internal documents. RAG vs fine tuning is the key decision here, and the right choice depends on freshness, governance, and output control.
If you are building an internal assistant that answers employee questions about policies, SOPs, onboarding, product docs, pricing rules, or compliance playbooks, you are optimizing for accuracy, freshness, and traceability. In most real company scenarios, those three are easier to achieve with Retrieval Augmented Generation (RAG) than with fine tuning. But fine tuning can still be valuable when used for the right purpose.
This guide breaks down what each approach is best at, how to choose, and how teams ship a reliable assistant without turning it into a long research project.

What RAG actually does
RAG is a system pattern, not a model change. When a user asks a question, your application retrieves the most relevant passages from your trusted sources (documents, PDFs, internal wiki, knowledge base), and the model answers using those passages as context.
Think of it as open book answering. The model is great at language, but it does not need to memorize your policies because it can reference them.
RAG is strongest when:
- Your knowledge changes often (policies, pricing, product updates)
- You need citations and traceability for governance
- You want fast iteration without retraining a model
- You want to reduce hallucinations by grounding answers in real content
What fine tuning actually does
Fine tuning changes model behavior by training it on examples. This works best for teaching the model a consistent style, tone, format, or workflow pattern. It is not the best first move for embedding a large and changing knowledge base, because knowledge becomes outdated and requires retraining cycles.
Fine tuning is strongest when:
- You need consistent output format (structured answers, JSON, templates)
- You want the assistant to follow strict response rules
- You have repeated workflows (triage, classification, routing, summarization)
- Prompting alone is not producing stable behavior
When teams ask us to choose RAG vs fine tuning, we usually start by checking how often the knowledge changes and whether the business needs citations for governance.
Need a reliable internal AI assistant that stays aligned with your latest policies?
At Dev Entities, We build RAG based knowledge assistants with citations, versioning, and strict accuracy guardrails so teams can use AI confidently in regulated or high stakes environments.
Get a free consultation: Share 3 sample documents and your top 10 internal questions. We will recommend the best approach (RAG, fine tuning, or hybrid) and map a production ready rollout plan.
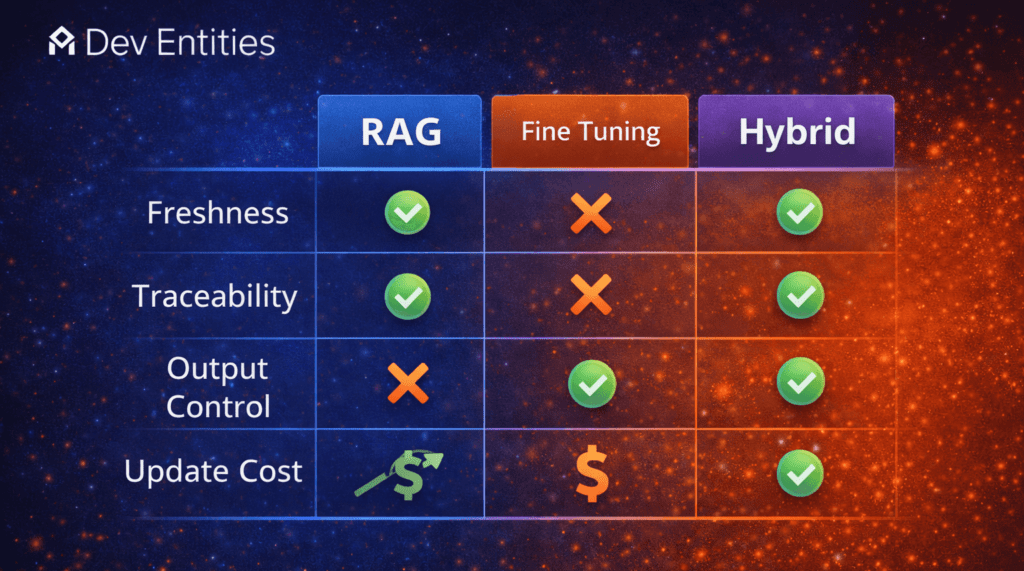
RAG vs fine tuning: a simple decision matrix
Use this practical rule set when choosing.
Choose RAG first when:
- Your source of truth is internal documents you control
- You care about answering with the latest policy and latest updates
- You need evidence, citations, and traceability
- Your content set is large and constantly evolving
Choose fine tuning first when:
- The assistant already knows the domain but the format is wrong
- You need stable structure, tone, and response style
- You are building classification or automation workflows
Choose a hybrid when:
- You need citations from internal sources (RAG)
- You also need consistent structured output (fine tuning)
- You need reliable tool calling and workflow control
Further reading
What actually reduces hallucinations
Teams often ask which approach reduces hallucinations more. For internal knowledge assistants, RAG usually wins because it forces the model to rely on retrieved evidence. But RAG does not automatically solve hallucinations. Reliability depends on the entire pipeline.
Key reliability levers:
- Proper chunking and document structure
- Metadata filters (region, department, version, effective date)
- Retrieval settings and reranking
- A strict rule to refuse when evidence is weak
- Continuous evaluation using a real question set
A production grade assistant needs a “no evidence, no answer” policy. When retrieval is weak, the system should ask clarifying questions or route to a human instead of guessing.
A rollout plan that works in real teams
Here is a practical rollout that teams can ship quickly.
- Define success
Collect 30 to 50 real internal questions, including tricky edge cases. This becomes your evaluation set. - Prepare authoritative sources
Decide what counts as truth. Remove duplicates. Tag documents by owner, version, and effective date. - Build the RAG pipeline
Ingest content, chunk and embed, store in a vector DB, and enforce metadata filtering. Ensure every answer can show citations. - Add governance rules
Implement confidence thresholds, refusal behavior, and escalation routes. - Evaluate and iterate
Run the evaluation set weekly and track correctness, citation quality, refusal quality, and latency. - Add fine tuning only when needed
Use fine tuning for stable structure, tone, or workflow reliability after your retrieval foundation is solid.
Retrieval augmented generation vs fine tuning: common mistakes to avoid
- Indexing everything without defining authoritative sources
- No versioning, causing outdated answers
- Chunking that separates policy statements from conditions
- Not filtering by region or product line
- Letting the model answer even when retrieval is weak
- Shipping without an evaluation set
Conclusion
RAG is usually the fastest and safest path to an internal knowledge assistant that stays up to date and explainable. Fine tuning is best used to standardize behavior and output, not as a replacement for a living knowledge base.
If you want reliable answers with governance, start with RAG, measure results, then layer in fine tuning when it adds value.
Want to validate feasibility quickly?
Book a free consultation and we will map a rollout plan, define success metrics, and outline the integration approach based on your current tools.